“源神”DeepSeek突破H800性能极限 FlashMLA开源引领算力成本新低
来源:量子位
DeepSeek开源周的第一天,降本增效的重磅技术正式公开——
FlashMLA,一举突破H800计算性能的上限。
网友纷纷表示震惊:这怎么可能??

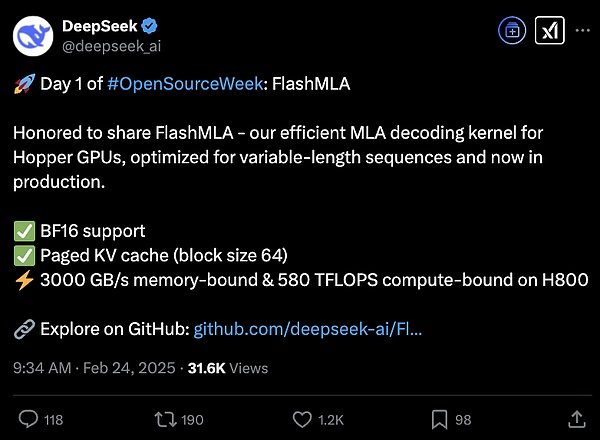
FlashMLA是专为Hopper GPU开发的高效MLA解码内核,针对可变长度序列进行了深度优化,目前已投入生产环境。
MLA(多头潜在注意力机制)是DeepSeek提出的创新性注意力架构。自V2版本起,MLA使DeepSeek在模型系列中大幅降低运行成本,同时保持与顶尖模型相当的计算和推理性能。
据官方介绍,使用FlashMLA后,H800的内存带宽可达到3000GB/s,计算性能高达580TFLOPS。
网友们纷纷点赞:向工程团队致以崇高的敬意!从Hopper的张量核中榨干了每一个FLOP。这才是将大语言模型(LLM)服务推向新高度的方式!

已有网友开始尝试使用。
开源首日:FlashMLA
目前,GitHub页面已更新。短短一小时内,项目Star数已突破1.2k。

此次发布的功能包括:
-
支持BF16;
-
分页KV缓存,块大小为64。
快速启动:
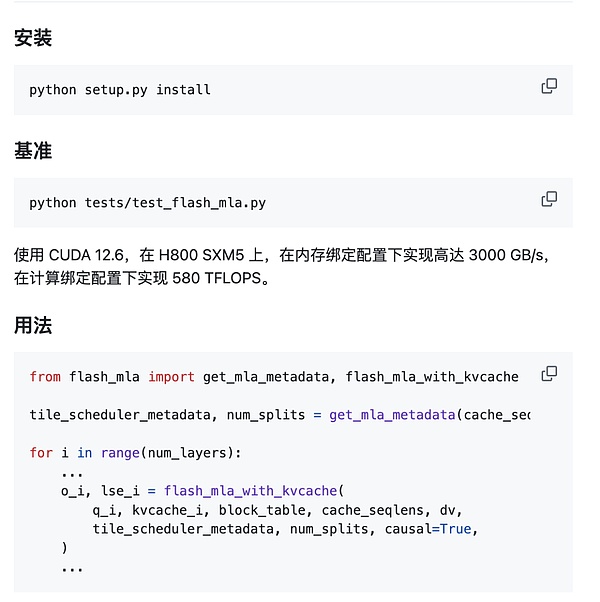
环境要求:
-
Hopper GPU
-
CUDA 12.3及以上版本
-
PyTorch 2.0及以上版本
在项目的最后,开发者表示,这一成果受到了FlashAttention 2&3和英伟达CUTLASS项目的启发。

FlashAttention是一种能够实现快速且内存高效的精确注意力算法,已被主流大模型广泛采用。其最新第三代版本可让H100的利用率飙升至75%,训练速度提升1.5-2倍,FP16下的计算吞吐量高达740TFLOPs/s,达到理论最大吞吐量的75%,而此前仅能达到35%。
FlashAttention的核心作者Tri Dao,是普林斯顿大学的知名学者,同时也是Together AI的首席科学家。
英伟达CUTLASS则是CUDA C++模板抽象的集合,用于在CUDA环境中实现高性能矩阵-矩阵乘法(GEMM)及相关的各种级别和规模的计算。
MLA:DeepSeek的基本架构
最后,我们来谈谈MLA(多头潜在注意力机制),这是DeepSeek系列模型的核心架构,旨在优化Transformer模型的推理效率与内存使用,同时保持高性能。
通过低秩联合压缩技术,MLA将多头注意力中的键(Key)和值(Value)矩阵投影到低维潜在空间,从而显著减少键值缓存(KV Cache)的存储需求。这种技术在长序列处理中尤为重要,因为传统方法需要存储完整的KV矩阵,而MLA通过压缩仅保留关键信息。
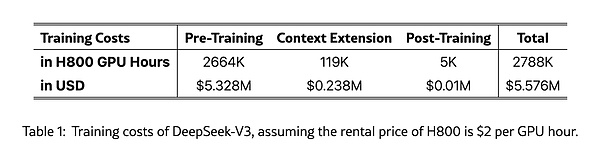
在V2版本中,这一创新性架构将显存占用降至过去最常用的MHA架构的5%-13%,实现了成本的大幅降低。其推理成本仅为Llama 370B的1/7、GPT-4 Turbo的1/70。
而在V3版本中,这一降本提速的效果更加显著,直接让DeepSeek吸引了全球目光。
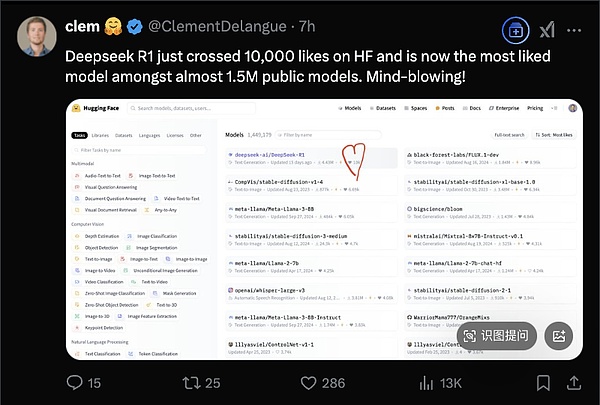
就在今天,DeepSeek-R1在HuggingFace上获得了超过10000个赞,成为该平台近150万个模型中最受欢迎的大模型。
HuggingFace CEO发文庆祝了这一喜讯。
The whale is making waves!鲸鱼正在掀起波浪!

接下来的四天,DeepSeek还会带来哪些惊喜呢?让我们拭目以待。
 币安网
币安网 欧易OKX
欧易OKX HTX
HTX Coinbase
Coinbase 芝麻开门
芝麻开门 Bitget
Bitget Bybit
Bybit 双子星(Gemini)
双子星(Gemini) Upbit
Upbit Crypto.com
Crypto.com 泰达币
泰达币 以太坊
以太坊 比特币
比特币 USD Coin
USD Coin First Digital USD
First Digital USD Solana
Solana 瑞波币
瑞波币 艾达币
艾达币 狗狗币
狗狗币 ChainLink
ChainLink