900个开源AI工具背后,我看到的趋势
文章来源: OneFlow
作者 | Chip Huyen
OneFlow编译
翻译|杨婷、宛子琳

四年前,我对开源机器学习生态系统进行了分析。自那时起,情况就发生了变化,所以这次我打算重新讨论这个话题,本次主要关注的是基础模型的技术栈。
我把完整的开源AI代码库列表放在了“llama-police”(https://huyenchip.com/llama-police,该列表每6小时更新一次。其余大部分也放在了我的GitHub“cool-llm-repos”(https://github.com/stars/chiphuyen/lists/cool-llm-repos)列表中。
(本文作者Chip Huyen是实时机器学习平台Claypot AI的联合创始人。本文经授权后由OneFlow编译发布,转载请联系授权。原文:https://huyenchip.com//2024/03/14/ai-oss.html)
数据
如果你现在觉得AI发展十分火爆,那是因为它确实如此。我在Github上以GPT、LLM和Generative AI为关键词进行检索,仅与GPT相关的就有约11.8万条结果。
为减少工作量,我将搜索范围限定在拥有至少500 star数的代码库。结果显示,与LLM相关的有590个,与GPT相关的有531个,与Generative AI相关的有38个。此外,我偶尔会查看GitHub Trending和社交媒体上的新代码库。
经过长时间的搜索,我找到了896个仓库。其中,有51个是教程(例如dair-ai/Prompt-Engineering-Guide)和聚合列表(例如f/awesome-chatgpt-prompts)。尽管这些教程和列表都很有帮助,但我更感兴趣的是软件,不过我还是将其放进了最终列表,只是最后的分析是基于其余845个软件库(截止本文发布)。
这个过程虽然痛苦,但很值得,因为我更深入地了解了人们正在研究的内容,开源社区的合作程度之高令人惊叹,也让我意识到中国的开源生态系统与西方存在很大差异。
(毫无疑问,我也遗漏了很多库。你可以在这里(https://forms.gle/1ijNSnizgWQaVYK16)提交缺失的代码库,该列表每天会自动更新。欢迎提交star数少于500的代码库,我会持续关注这些仓库,并在它们达到500 star时将其添加到列表中!)
新的AI技术栈
我认为,AI技术栈包含四个层级:基础设施层、模型开发层、应用开发层和应用层。
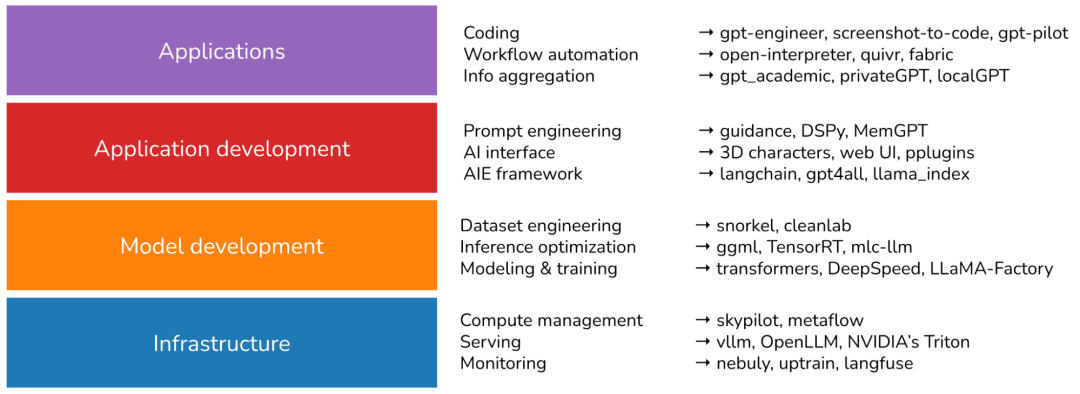
1.基础设施层
基础设施是AI技术栈的底层,包括用于Serving的工具(例如vLLM、NVIDIA的Triton)、计算管理(例如SkyPilot)、向量搜索和数据库(例如Faiss、Milvus、Qdrant、LanceDB)等。
2.模型开发层
模型开发层提供了开发模型的工具,包括建模和训练框架(Transformers、Pytorch、DeepSpeed)、推理优化(如GGML、Openai/Triton)、数据集工程,评估等。任何涉及改变模型权重的操作都发生在这一层,包括微调。
3.应用开发层
在应用开发层,任何人都可以基于现成的模型开发应用程序。在过去的两年里,这一层的发展动态最多,并且仍在快速演进。这一层也被称为AI工程(AI Engineering)。
应用开发包括提示工程(Prompt Engineering)、RAG(Retrieve、Add、Generate)和AI界面(AI Interface)等。
4.应用层
应用层有许多基于现有模型构建的开源应用程序,其中最流行的应用类型包括编码、工作流自动化、信息聚合等。
除这四层外,还有另一个类别,即模型存储库(Model Repos)。这些存储库由公司和研究人员创建,用于分享与他们模型相关的代码。这一类别的存储库示例包括CompVis/stable-diffusion、openai/whisper和facebookresearch/llama。
AI技术栈的演进
我绘制了每一类别中代码库数量的累积月度图。在2023年推出Stable Diffusion和ChatGPT之后,新工具的数量呈爆炸式增长。2023年9月后,曲线似乎开始趋于平缓,这背后可能有三个潜在原因:
- 我的分析中仅包含star数500以上的库,而代码库积累这么多star需要时间。
- 大部分容易获得的成果(low-hanging fruits)已被收割,剩下的项目需要付出更多的努力来构建,因此能够构建它们的人更少。
- 人们意识到在生成式人工智能领域很难保持竞争力,因此激动的情绪已平息。2023年初,我与公司的所有人工智能对话都集中在生成式人工智能上,但最近的交流更加务实,有些公司甚至提到了Scikit-learn。我希望在几个月后重新审视这一点,以验证这种情况是否属实。
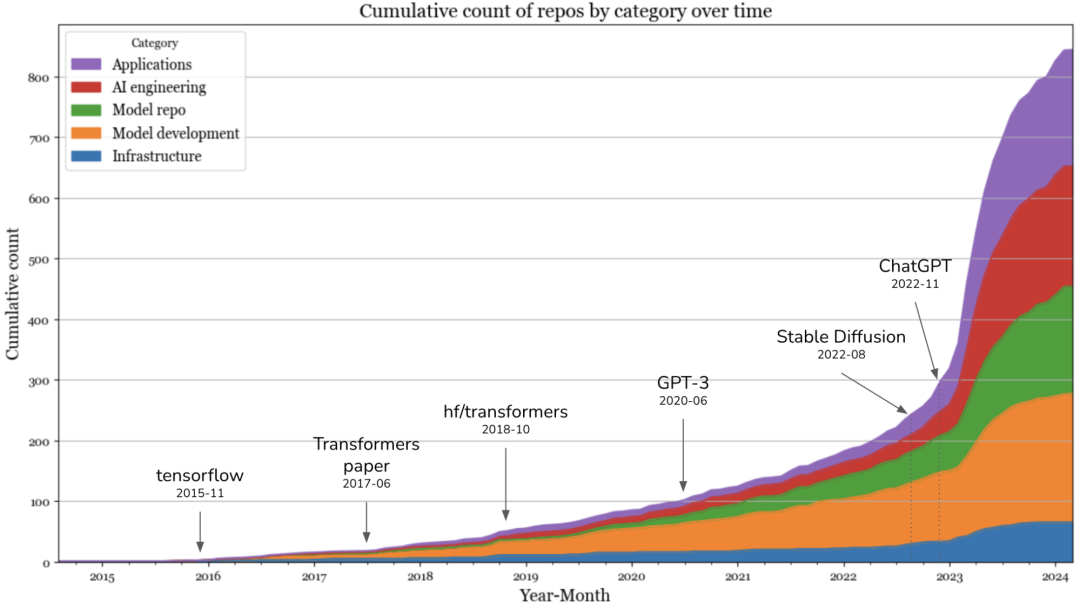
在2023年,增长最快的是应用层和应用程序开发层。基础设施层出现了一些增长,但远不及其他层的增长水平。
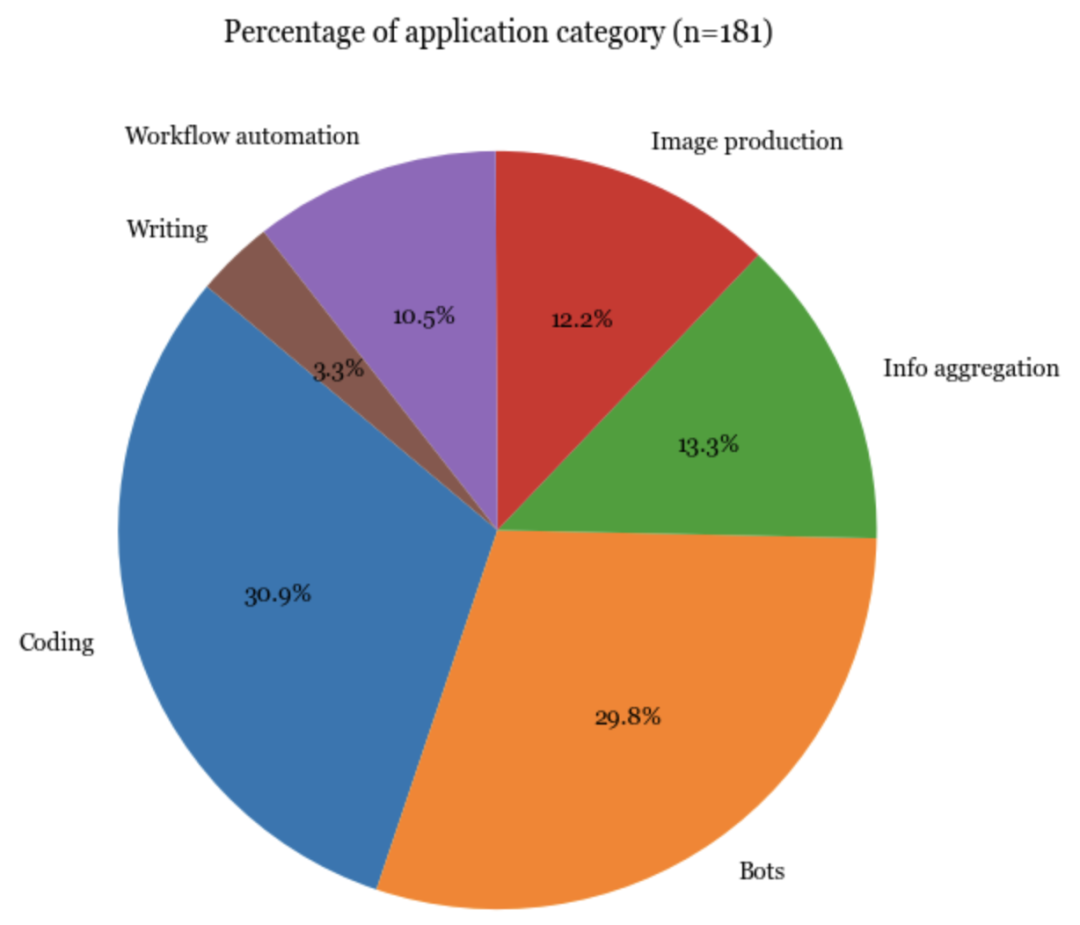
应用
毫不奇怪,最受欢迎的应用类型是编码、机器人(例如角色扮演、WhatsApp机器人、Slack机器人)以及信息聚合(例如“将其连接到我们的Slack,并要求它每天总结消息”)。
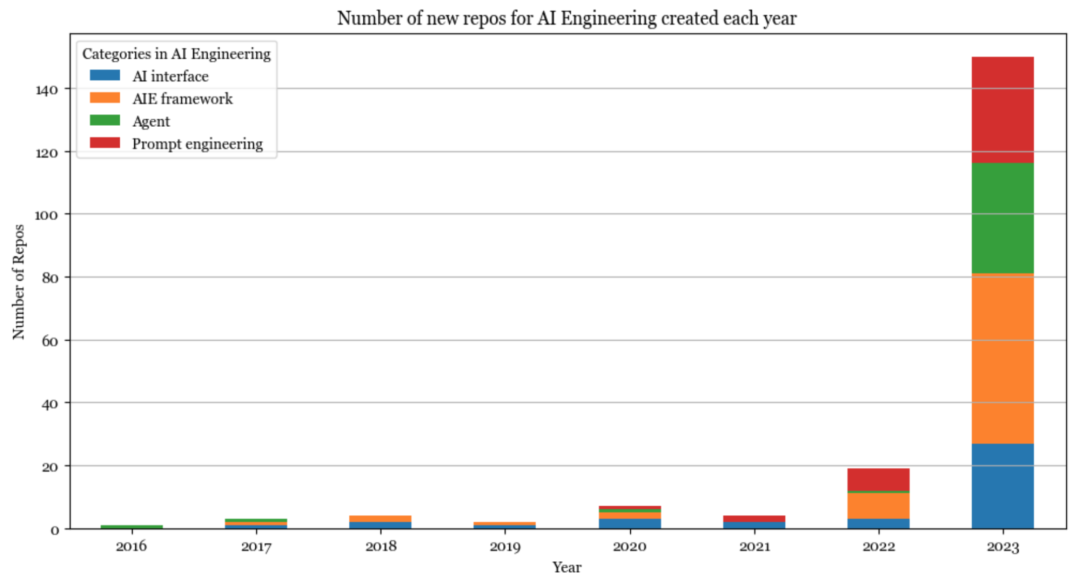
AI工程化
2023年是AI工程化的一年。由于许多工具比较相似,很难对其进行分类。目前我将它们分为以下几类:提示工程、AI界面、智能体(Agent)和AI工程(AIE)框架。
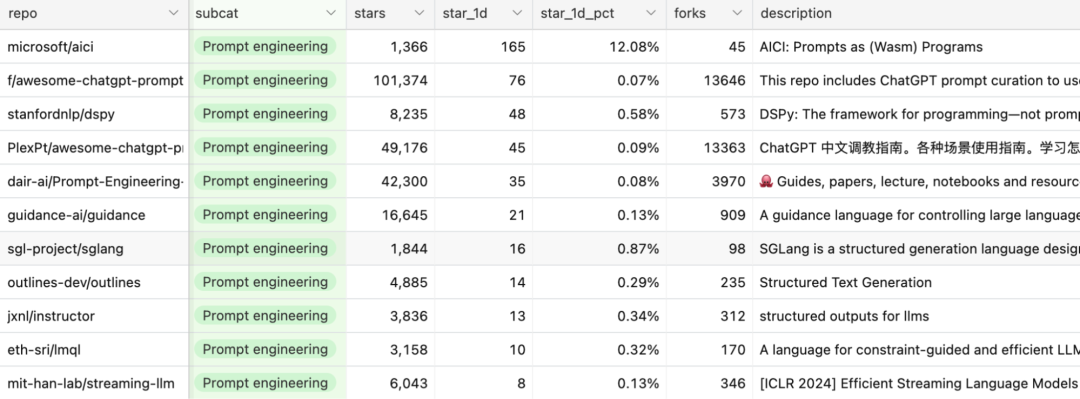
提示工程远不止是简单地调整提示,涵盖了诸如约束采样(结构化输出)、长期记忆管理、提示测试与评估等内容。
AI界面提供了一个界面,可以让最终用户与AI应用程序进行交互。这是我最感兴趣的一个类别。一些日益受到欢迎的界面包括:
- Web和桌面应用程序。
- 浏览器扩展,让用户在浏览网页时快速查询AI模型。
- Slack、Discord、微信和WhatsApp等聊天应用程序上的机器人。
- 插件:让开发人员将AI应用程序嵌入到VSCode、Shopify和Microsoft Office等应用程序中。插件常用于可以使用工具完成复杂任务的AI应用(智能体)中。
AIE框架是一个统称,用来指代所有能够帮助开发AI应用程序的平台。其中许多平台都是围绕RAG构建的,但也提供诸如监控、评估等其他工具。
智能体是一个捉摸不定的类别,因为许多智能体工具实际上只是复杂的提示工程,可能包含约束生成(例如,模型只能输出预定的动作)和插件集成(例如,让智能体使用工具)。
模型开发层
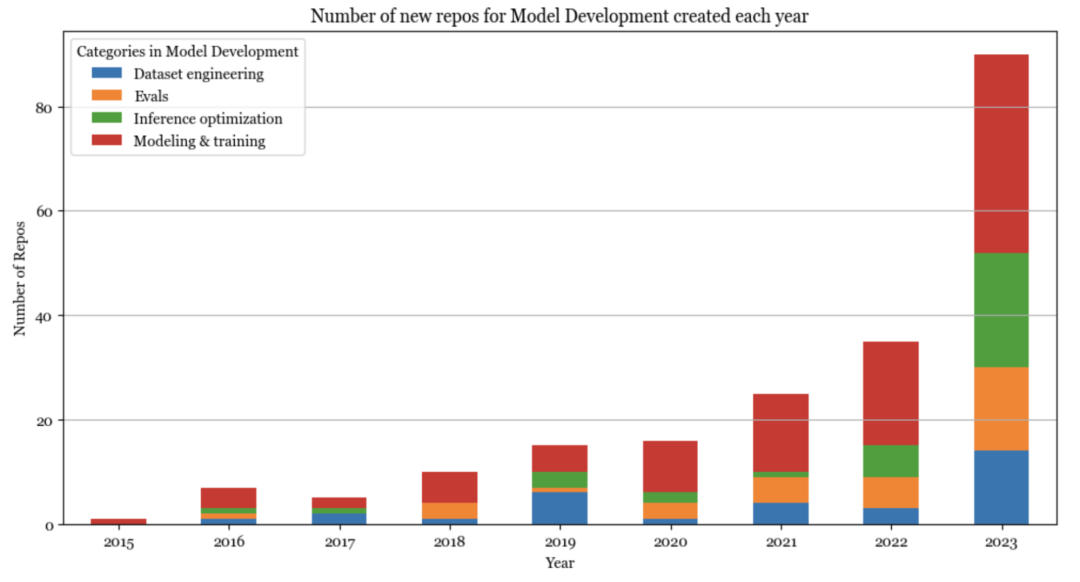
在ChatGPT出现之前,模型开发主导了AI技术栈。2023年,模型开发的最大增长源自于对推理优化、评估和参数高效微调(归类为建模和训练)日益增加的兴趣。
推理优化一直以来都非常重要,但如今基础模型的规模使得它对时延和成本变得至关重要。虽然优化的核心方法仍然保持不变(量化、低秩分解、剪枝、蒸馏),但许多新的技术已经被开发,特别是针对Transformer架构和新一代硬件。例如,2020年,16位量化被认为是最先进的技术,而如今又出现了2位量化甚至更低的量化技术。
同样,模型评估一直以来也十分重要,但如今许多人把模型视为黑匣子,因此评估的重要性变得愈发突出。现在出现了许多新的评估基准和评估方法,例如比较评估(如Chatbot Arena)和将AI作为裁判(AI-as-a-judge)的评估方法。
基础设施层
基础设施层主要涉及管理数据、计算以及用于服务、监控和其他平台工作的工具。尽管生成式人工智能带来了诸多变化,但开源AI基础设施层基本保持不变。这可能是因为基础设施产品通常不是开源的,因此在开源领域中并没有出现太多变化。
基础设施层中的最新类别是向量数据库,其中包括Qdrant、Pinecone和LanceDB等公司。然而,许多人认为,这根本不应该成为一个类别。向量搜索已经存在很长时间了。与其仅仅为了向量搜索构建新的数据库,不如像DataStax和Redis这样的现有数据库公司将向量搜索整合到现有的数据库中。
开源AI开发者
像许多其他事物一样,开源软件也遵循长尾分布,由少数账户掌控着大部分的代码库。
一人创造价值数十亿美元的公司?
有845个代码库托管在594个独特的GitHub账户上,其中20个账户至少拥有4个代码库。这些排名前20的账户托管了195个代码库,占列表上全部代码库的23%,这195个代码库共获得了165万star数。
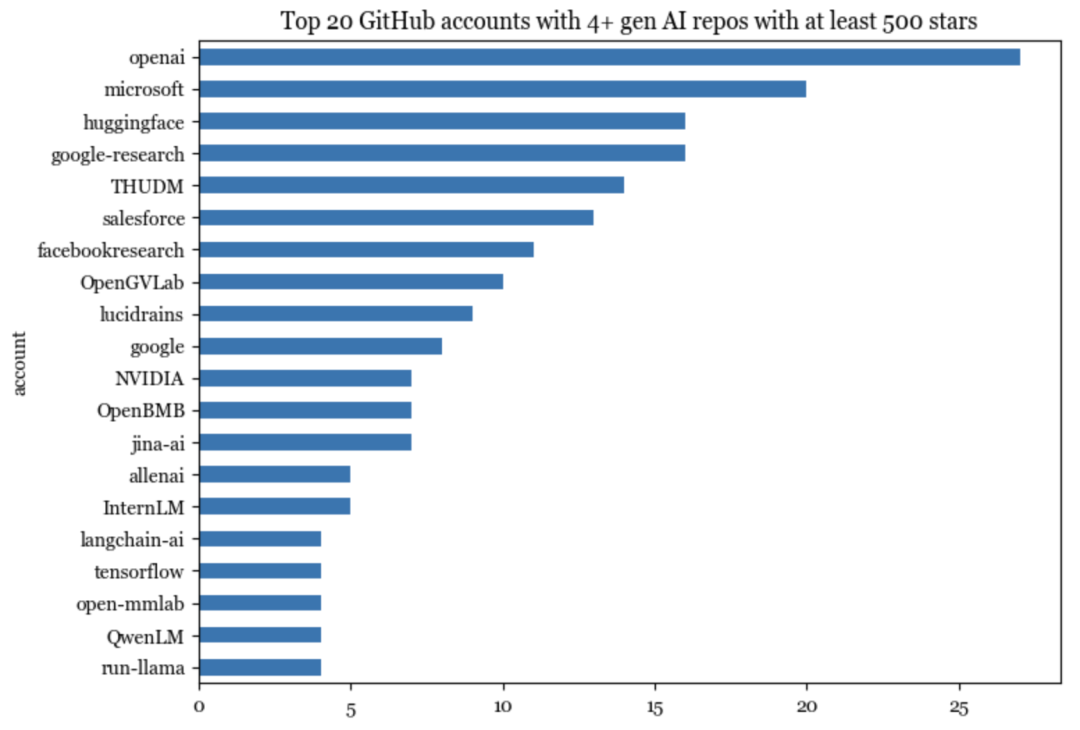
在Github上,账户可以由组织或个人所有。在这些排名Top 20的顶级账户中,有19个属于组织,其中3个属于谷歌,分别是Google-research,Google和Tensorflow。
在排名top 20的账户中,唯一的个人账户是lucidrains。在拥有最多star数的top 20账户中(仅计算通用人工智能代码库),只有4个是个人账户:
- lucidrains(Phil Wang):能以极快的速度实现SOTA模型。
- ggerganov(Georgi Gerganov):一位物理学出身的优化专家。
- Illyasviel(Lyumin Zhang):创建了Foocus和ControlNet,目前在斯坦福大学攻读博士。
- xtekky:一位全栈开发者,创建了gpt4free。
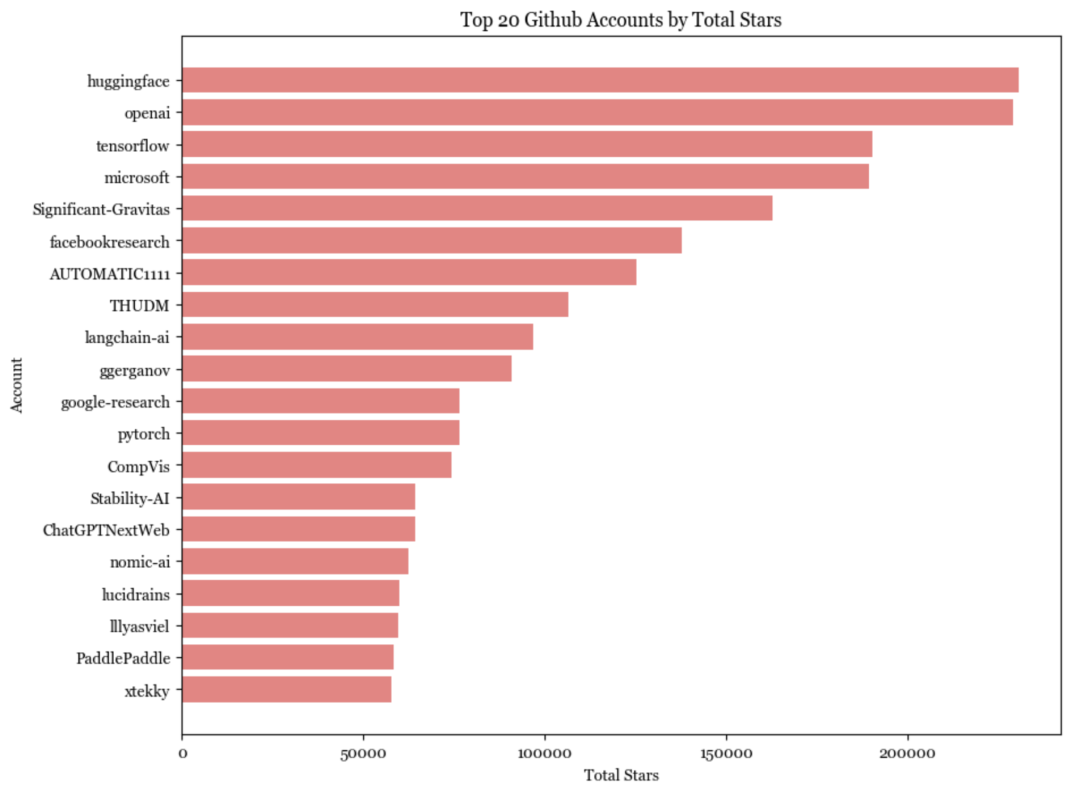
自然地,在技术栈所处的层级越低,个人开发的难度就越大。因此基础设施层的软件最不可能由个人账户发起和托管。然而,超过一半的应用程序由个人托管。
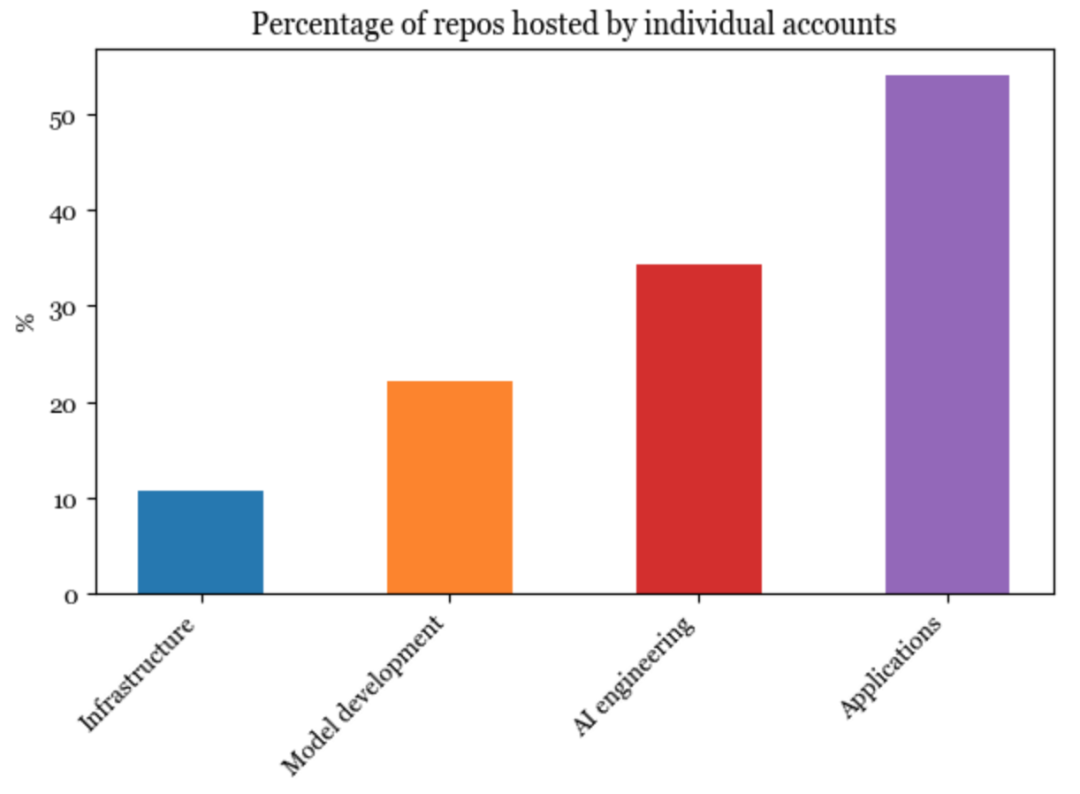
由个人发起的应用程序平均获得的star数比由组织发起的更多。许多人推测将会出现众多市值不菲的个人公司(参考OpenAI CEO Sam Altman的采访 https://fortune.com/2024/02/04/sam-altman-one-person-unicorn-silicon-valley-founder-myth/以及Reddit上的讨论)。我认为,这种推测可能是正确的。
100万次commit
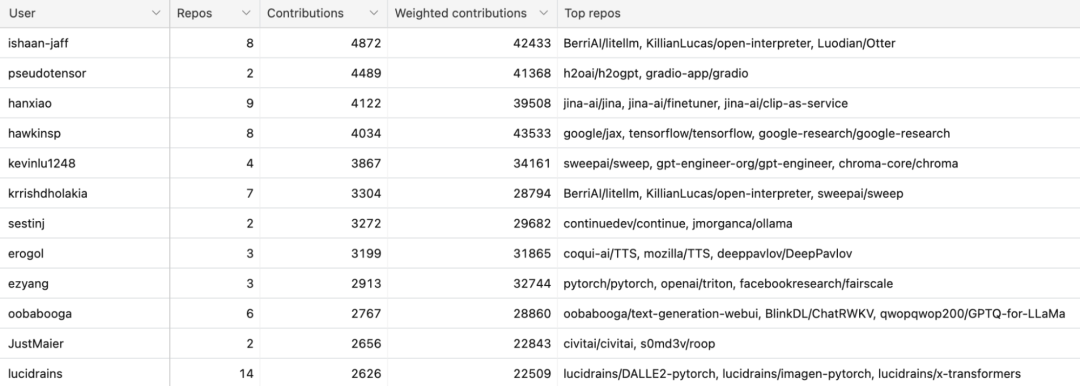
超过两万名开发人员为这845个库做出了贡献。他们共计完成了近100万次commmit!
其中排名前50位的活跃开发人员完成了超10万次commit,平均每人超过2000次。下图为前50位最活跃的开源开发人员的完整列表。
中国不断壮大的开源生态系统
众所周知,长期以来中国的AI生态系统与美国有所差异,(我在2020年的一篇博客文章中也提到过这一点)。当时,我的印象是GitHub在中国的使用并不广泛,而我的看法可能受到了中国在2013年禁止使用GitHub的影响。
然而,如今情况已经发生了改变。在GitHub上有许多针对中国受众的热门AI代码库,其描述均由中文编写。其中一些代码库是为中文或中英文混合开发的模型而设立的,如Qwen、ChatGLM3、Chinese-LLaMA等。
在美国,虽然许多研究实验室已经放弃了基于循环神经网络(RNN)架构的语言模型,但基于RNN的模型系列的RWKV仍然很受欢迎。
此外,还有一些AI工程工具能够将AI模型集成到中国的主流产品中,如微信、QQ、钉钉等。许多热门的提示工程工具在中国也有镜像。
在GitHub上排名前20的账户中,有6个来自中国:
- THUDM:清华大学知识工程组(KEG)和数据挖掘团队。
- OpenGVLab:上海人工智能实验室的通用视觉团队。
- OpenBMB:由ModelBest和清华大学NLP组共同创建的大模型基地开放实验室。
- InternLM:来自上海的人工智能实验室。
- OpenMMLab:来自香港中文大学。
- QwenLM:阿里巴巴的人工智能实验室,发布了Qwen模型系列。
快速崛起,短暂辉煌
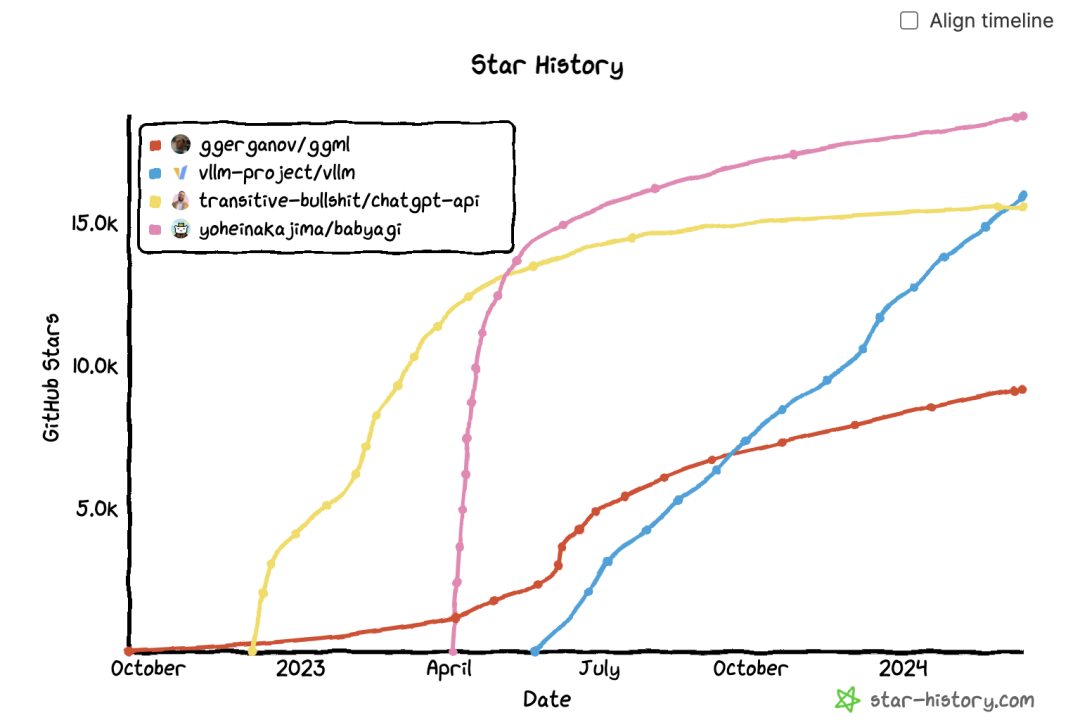
去年,我观察到许多代码库在短期内迅速吸引了大量关注,但随后便快速衰落。我的一些朋友称之为“炒作曲线”。在这845个至少拥有500 star数的GitHub代码库中,有158个库(占18.8%)在过去24小时内没有获得任何新的star,有37个库(占4.5%)在过去一周内没有获得任何新的star。
以下是其中两个代码库的增长轨迹示例,与其他两个更为持久的软件增长曲线进行比较。尽管这里展示的两个示例已不再使用,但在这里用作开源社区的例子非常典型,并且其作者们能够如此快速地推出这些项目,实在是令人赞叹。
个人最看好的创意
社区正在开发许多酷炫的创意,以下是我最看好的一部分:
- Batch推理优化:FlexGen、llama.cpp
- 采用Medusa、LookaheadDecoding等技术实现更快的解码器
- 模型合并:mergekit
- 受限采样:outlines、guidance、SGLang
- 看似小众但解决问题非常出色的工具,如einops和safetensors
结论
尽管本文的分析仅涉及845个代码库,但我实际上浏览了数千个代码库,这有助于我全面了解看似庞大的AI生态系统。希望这份列表对你有所帮助,如果你发现了遗漏的仓库,请告诉我,我会将它们添加到列表中。
【OneDiff v1.0发布(生产环境稳定加速SD&SVD)】本次更新包含以下亮点,欢迎体验新版本:github.com/siliconflow/onediff
- OneDiff质量评估
- 重复利用编译图
- 改进对Playground v2.5的支持
- 支持ComfyUI-AnimateDiff-Evolved
- 支持ComfyUI_IPAdapter_plus
- 支持Stable Cascade
- 提高了VAE的性能
- 为OneDiff企业版提供量化工具
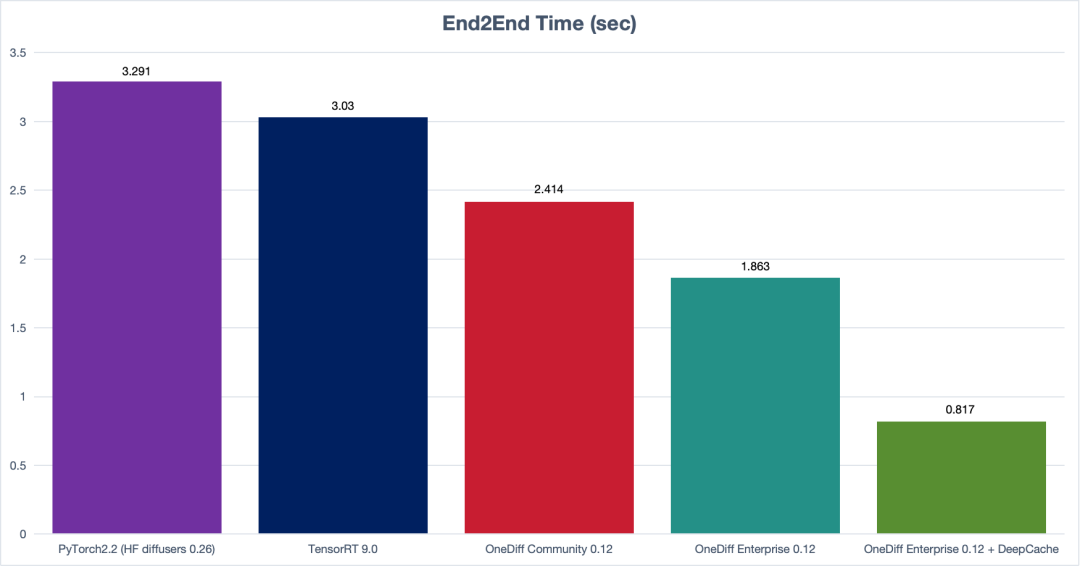
(SDXL E2E Time)
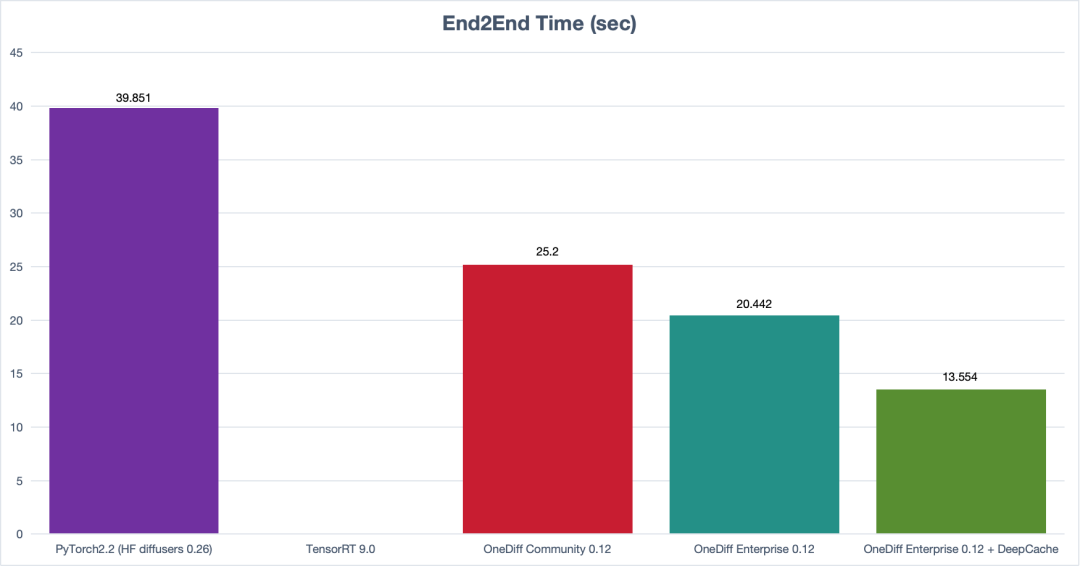
(SVD E2E Time)
 币安网
币安网 欧易OKX
欧易OKX HTX
HTX Coinbase
Coinbase 大门
大门 Bitget
Bitget Bybit
Bybit K网(Kraken)
K网(Kraken) 双子星(Gemini)
双子星(Gemini) Upbit
Upbit 泰达币
泰达币 以太坊
以太坊 比特币
比特币 Solana
Solana USD Coin
USD Coin 瑞波币
瑞波币 币安币
币安币 First Digital USD
First Digital USD 狗狗币
狗狗币 OFFICIAL TRUMP
OFFICIAL TRUMP