上海AI实验室等开源,音频、音乐统一开发工具包Amphion
原文来源:AIGC开放社区

图片来源:由无界 AI生成
上海AI实验室、香港中文大学数据科学院、深圳大数据研究院联合开源了一个名为Amphion的音频、音乐和语音生成工具包。
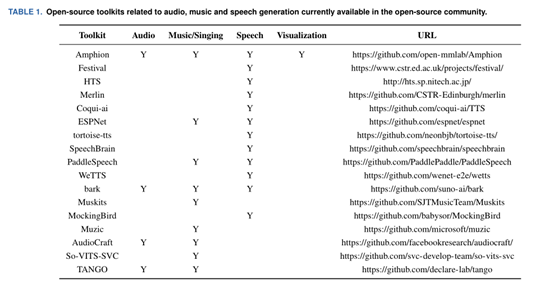
Amphion可帮助开发人员研究文本生成音频、音乐等与音频相关的领域,可以在一个框架内完成,以解决生成模型黑箱、代码库分散、缺少评估指标等难题。
Amphion包含了数据处理、通用模块、优化算法等基础设施。同时针对文本到语音、歌声转换、文本到音频生成等任务,提供了特定的框架、模型和开发说明,还内置了各类神经语音编解码器和评价指标。
尤其是对于那些刚接触生成式AI开发的新手来说,Amphion非常容易上手。
开源地址:https://github.com/open-mmlab/Amphion
论文地址:https://arxiv.org/abs/2312.09911
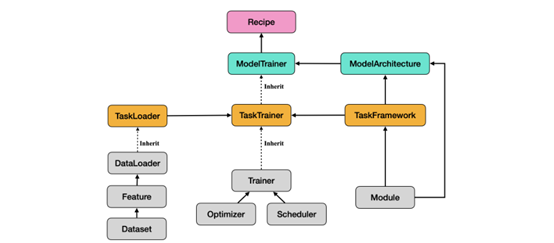
以下是Amphion包含的各种模型
文本到语音合成
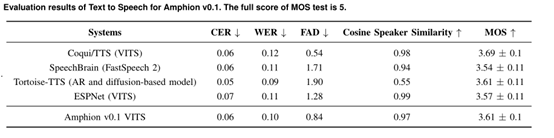
Amphion内置的文本到语音合成模型,涵盖从传统到当前最先进的技术。例如,FastSpeech 2使用前馈式Transformer架构实现快速语音合成;
VITS融合了条件变分自编码器,可实现端到端的语音合成;Vall-E使用神经编解码器语言模型一键实现零资源的语音合成;NaturalSpeech 2利用潜在扩散模型合成高质量语音。
开发者可根据业务需求,选择使用不同的模型进行语音合成。
歌声转换
Amphion提供了提取说话人无关表示的各类基于内容的特征,例如,来自WeNet、Whisper和ContentVec的预训练语音特征。
同时实现了多种声学解码器架构,比如基于扩散模型、变压器和变分自编码器的方法。
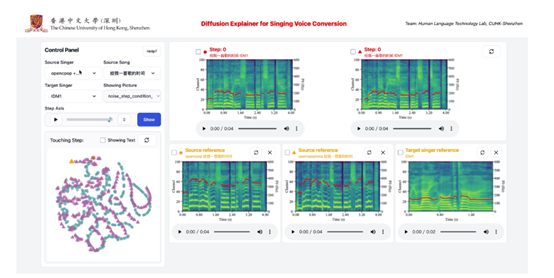
此外,借助内置的神经语音编解码器合成声波输出,开发者可以灵活配置不同模块,进行不同歌声风格转换。
文本到音频生成
Amphion使用了主流的潜在扩散生成模型。该模型包含一个将频谱映射到潜空间的变分自动编码器,一个接受文本并输出条件的T5编码器,以及一个扩散网络生成最终音频。
用户只需给出音频描述文本,就可以生成语义一致的背景音效。
神经语音编解码器
Amphion提供了丰富的编解码器算法选项,涵盖主流的自动回归模型、流模型、对抗生成模型、扩散模型等。
例如,WaveNet使用膨胀卷积实现高质量语音合成;HiFi-GAN应用多尺度判别器实现高保真的语音重构等,可满足不同业务场景的需求。
性能评估模块
为了帮助开发者全面评估生成语音的质量和性能,Amphion提供了丰富的评估模块。
评估基频建模、能量建模、频谱失真、可懂度等语音维度,可帮助开发者简单直观地比较不同模型的性能。
开发团队表示,未来,会持续更新这个工具包,加入更多与语音相关的模型,打造成最好用的开源语音工具包之一。
 币安网
币安网 欧易OKX
欧易OKX HTX
HTX Coinbase
Coinbase 大门
大门 Bitget
Bitget Bybit
Bybit K网(Kraken)
K网(Kraken) 双子星(Gemini)
双子星(Gemini) Upbit
Upbit 泰达币
泰达币 以太坊
以太坊 比特币
比特币 Solana
Solana USD Coin
USD Coin 瑞波币
瑞波币 币安币
币安币 First Digital USD
First Digital USD 狗狗币
狗狗币 大零币
大零币