英伟达GTC 2025:Blackwell架构引领算力革命,硅光芯片与具身智能成未来焦点
作者:苏扬、郝博阳;来源:腾讯科技
作为AI时代的“卖铲人”,黄仁勋和他的英伟达,始终坚信算力永不眠。
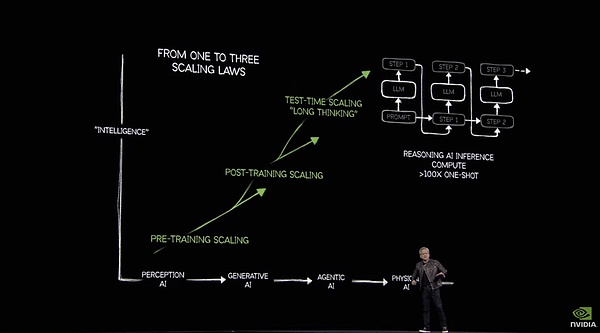
黄仁勋在GTC演讲中称推理让算力需求暴增100倍
在今天的GTC大会上,英伟达推出了全新的Blackwell Ultra GPU及基于此架构的多种产品形态,包括推理专用服务器SKU和RTX系列全家桶。这些创新产品展示了英伟达对算力需求的深刻理解,但更重要的是如何将这些算力合理有效地利用起来。
黄仁勋认为,通往AGI需要算力,具身智能机器人需要算力,构建Omniverse与世界模型更需要源源不断的算力。而最终人类想要构建一个虚拟的“平行宇宙”,可能需要过去100倍的算力。
Blackwell全家桶上线
1)年度“核弹”Blackwell Ultra在挤牙膏
去年GTC发布Blackwell架构并推出GB200芯片,今年正式名称调整为Blakwell Ultra。相比上一代,主要升级在于HBM内存。
一句话理解就是,Blackwell Ultra= Blackwell大内存版本。
Blackwell Ultra由两颗台积电N4P(5nm)工艺制造的Blackwell架构芯片+Grace CPU封装,并搭配了12层堆叠的HBM3e内存,显存提升至288GB,支持第五代NVLink,可实现1.8TB/s的片间互联带宽。

NVLink历代性能参数
基于存储的升级,Blackwell GPU的FP4精度算力可以达到15PetaFLOPS,基于Attention Acceleration机制的推理速度比Hopper架构芯片提升2.5倍。
2)Blackwell Ultra NVL72:AI推理专用机柜

Blackwell Ultra NVL72官方图
Blackwell Ultra NVL72机柜由18个计算托盘构成,每个计算托盘包含4颗Blackwell Ultra GPU+2颗Grace CPU,总计72颗GPU+36颗CPU,显存达到20TB,总带宽576TB/s,外加9个NVLink交换机托盘(18颗NVLink交换机芯片),节点间NVLink带宽130TB/s。
机柜内置72张CX-8网卡,提供14.4TB/s带宽,Quantum-X800 InfiniBand和Spectrum-X 800G以太网卡则可以降低延迟和抖动,支持大规模AI集群。此外,还整合了18张BlueField-3 DPU用于增强多租户网络、安全性和数据加速。
根据官方信息,Blackwell Ultra NVL72方案在推理任务中的表现远超前代产品,如6710亿参数DeepSeek-R1的推理,基于H100每秒100tokens,而Blackwell Ultra NVL72可达每秒1000 tokens。
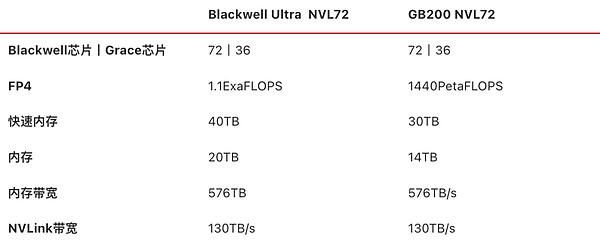
Blackwell Ultra NVL72和GB200 NVL72硬件参数
3)提前预告真“核弹”GPU Rubin芯片
按照英伟达路线图,GTC2025主打Blackwell Ultra。不过,黄仁勋也透露了2026年上市的基于Rubin架构的下一代GPU及更强的机柜Vera Rubin NVL144——72颗Vera CPU+144颗 Rubin GPU,采用288GB显存的HBM4芯片,显存带宽13TB/s,搭配第六代NVLink和CX9网卡。
这款产品的FP4精度推理算力达到3.6ExaFLOPS,FP8精度训练算力达到1.2ExaFlOPS,性能是Blackwell Ultra NVL72的3.3倍。

英伟达官方提供的Rubin Ultra NVL144和Rubin Ultra NVL576参数
英伟达Photonics:站在队友肩膀上的CPO系统
光电共封模块(CPO)的概念简单来说就是将交换机芯片和光学模块共同封装,充分利用光信号的传输性能。
今年GTC上,英伟达一次性推出了Quantum-X硅光共封芯片、Spectrum-X硅光共封芯片以及衍生出的三款交换机产品:Quantum 3450-LD、Spectrum SN6810和Spectrum SN6800。
-
Quantum 3450-LD:144个800GB/s端口,背板带宽115TB/s,液冷
-
Spectrum SN6810:128个800GB/s端口,背板带宽102.4TB/s,液冷
-
Spectrum SN6800:512个800GB/s端口,背板带宽409.6TB/s,液冷

GTC上展示的两款硅光共封芯片Quantum-X、Spectrum-X参数
模型效率PK DeepSeek:软件生态发力AI Agent

黄仁勋在现场描绘AI infra的“大饼”
1)Nvidia Dynamo,英伟达在推理领域构建的新CUDA
Nvidia Dynamo是一个专为推理、训练和跨整个数据中心加速而构建的开源软件,其性能数据相当震撼:在现有Hopper架构上,Dynamo可让标准Llama模型性能翻倍。而对于DeepSeek等专门的推理模型,NVIDIA Dynamo的智能推理优化还能将每个GPU生成的token数量提升30倍以上。
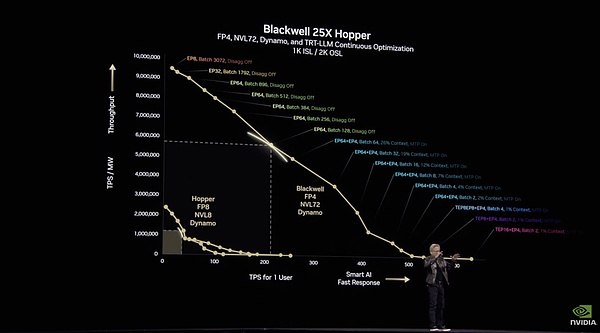
黄仁勋演示加了Dynamo的Blackwell能超过25倍的Hopper
Dynamo通过分布化的方式分配LLM的不同计算阶段,使每个阶段都能独立优化,提高吞吐量并加快响应速度。
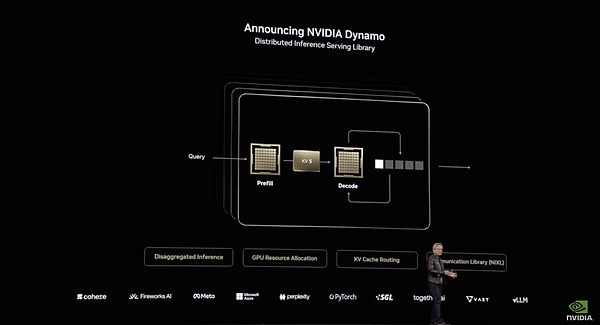
Dynamo的系统架构
2)Llama Nemotron新模型秀高效,但还是打不过DeepSeek
英伟达在这次GTC上用一款新模型Llama Nemotron主打高效、准确。它是从Llama系列模型衍生而来,经过算法修剪优化,更加轻量级,仅有48B参数。
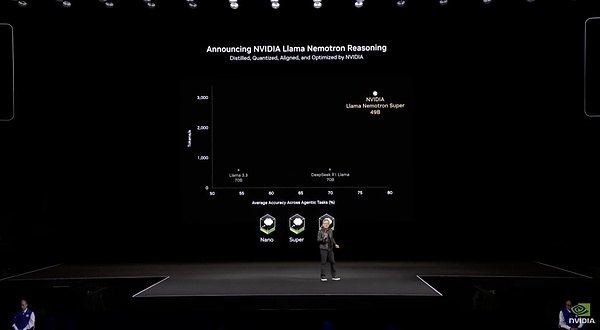
Llama Nemotron的具体数据
人形机器人基础模型发布 英伟达要做具身生态全闭环
1)Cosmos,让具身智能理解世界
Cosmos是一个能通过当前画面预测未来画面的模型,它可以从文本/图像输入数据生成详细的视频,并结合动作提示预测场景演变。
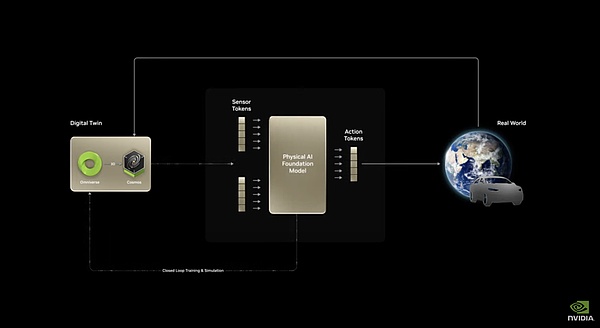
Cosmos的基本架构
2)Isaac GR00T N1,世界第一个人形机器人基础模型
Isaac GR00T N1采用双系统架构,有快速反应的“系统1”和深度推理的“系统2”,能够处理抓取、移动、双臂操作等通用任务。
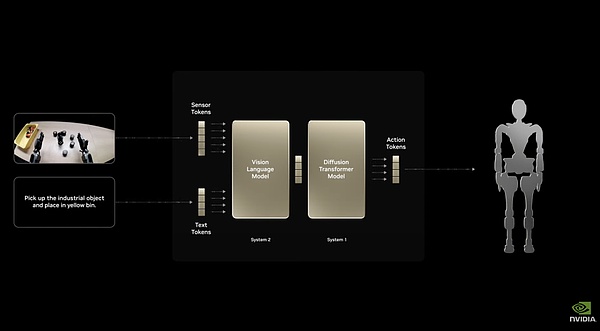
Isaac GR00T N1的双系统架构
结语
如果单纯对比上一代Blackwell芯片,Blackwell Ultra在硬件上确实匹配不上之前的“核弹”、“王炸”这些形容词,甚至有些挤牙膏的味道。
但如果从路线图规划的角度来看,这些又都在黄仁勋的布局之中,明年、后年的Rubin架构,从芯片工艺,到晶体管,再到机架的集成度,GPU互联和机柜互联等规格都会有大幅度提升,用中国人习惯说的叫“好戏还在后头”。
 币安网
币安网 欧易OKX
欧易OKX HTX
HTX Coinbase
Coinbase 大门
大门 Bitget
Bitget Bybit
Bybit 双子星(Gemini)
双子星(Gemini) Upbit
Upbit Crypto.com
Crypto.com 泰达币
泰达币 以太坊
以太坊 比特币
比特币 Solana
Solana USD Coin
USD Coin 瑞波币
瑞波币 狗狗币
狗狗币 First Digital USD
First Digital USD 币安币
币安币 莱特币
莱特币