DeepSeek开源第三弹:V3/R1训练推理核心工具DeepGEMM发布,代码仅300行
来源:量子位
在开源周的第三天,DeepSeek团队正式发布了其用于训练和推理V3/R1模型的核心工具——DeepGEMM。这是一个专注于FP8通用矩阵乘法(GEMM)的高性能库,支持密集矩阵(dense)和混合专家(MoE)矩阵乘法运算。
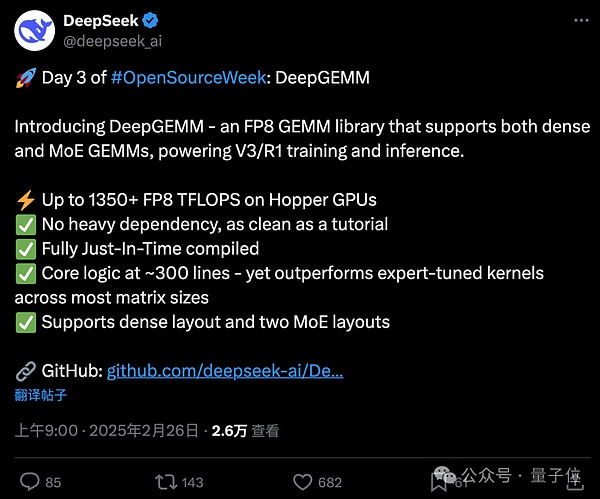
GEMM(通用矩阵乘法)是线性代数中的基础运算,在科学计算、机器学习以及深度学习等领域中扮演着重要角色。然而,由于其计算量庞大,性能优化成为关键挑战。DeepGEMM以其“高性能+低成本”的特性脱颖而出,以下是其主要亮点:
-
高性能:在Hopper架构的GPU上,DeepGEMM能够实现高达1350+ FP8 TFLOPS的性能。
-
简洁性:核心逻辑仅约300行代码,但性能却优于专家调优的内核。
-
即时编译(JIT):采用完全即时编译的方式,能够在运行时动态生成优化代码,适应不同硬件和矩阵大小。
-
无重依赖:设计轻量级,没有复杂依赖关系,简化了部署和使用。
-
支持多种矩阵布局:包括密集矩阵布局和两种MoE布局,适用于混合专家模型等多种场景。
简单来说,DeepGEMM主要用于加速深度学习中的矩阵运算,特别适合大规模模型的训练和推理任务,显著提升了计算效率。
这次开源引发了广泛讨论。有网友将DeepGEMM比作数学界的超级英雄,称赞其速度超越计算器;也有人将其发布形容为“量子态稳定到新的现实”,对其即时编译的设计表示高度认可。
当然,也有部分网友对英伟达股票的未来表现表达了担忧。
深入了解DeepGEMM
DeepGEMM是一个专为高效FP8通用矩阵乘法(GEMMs)打造的库,具备细粒度缩放功能,源自DeepSeek V3的研发成果。
它不仅支持普通矩阵乘法,还能处理MoE分组矩阵乘法,并通过CUDA编写,利用轻量级即时编译(JIT)模块实现运行时编译。
目前,DeepGEMM仅支持英伟达Hopper张量核心。为解决FP8张量核心累积计算精度不足的问题,采用了CUDA核心的两级累积方法。
尽管借鉴了CUTLASS和CuTe的部分理念,DeepGEMM并未过度依赖它们的模板或代数运算,而是保持了极高的简洁性,核心内核函数仅约300行代码。
性能方面,团队在H800 GPU上测试了DeepSeek-V3/R1推理中可能用到的所有矩阵形状。结果表明,DeepGEMM最高计算性能可达1358 TFLOPS,内存带宽最高达2668 GB/s,与基于CUTLASS 3.6的优化实现相比,加速比最高可达2.7倍。
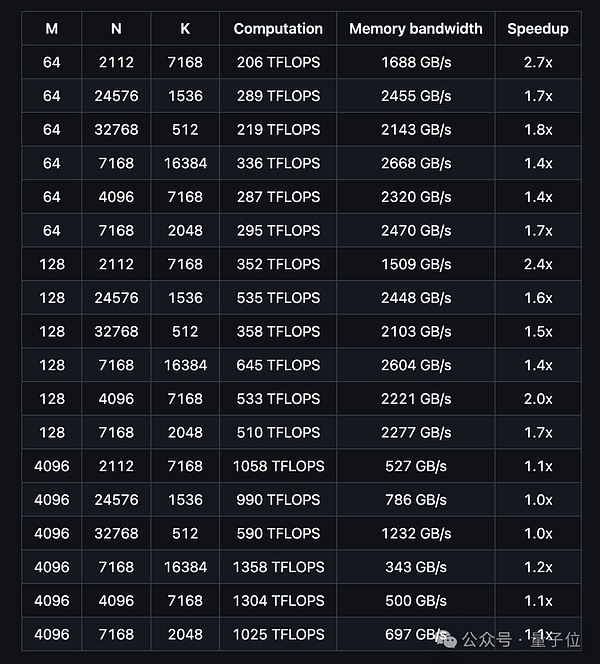
此外,DeepGEMM在支持MoE模型的连续布局和掩码布局时也表现出色:
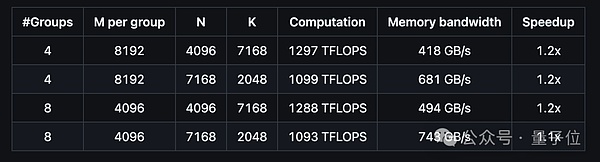
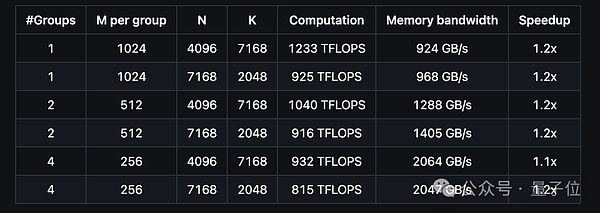
如何使用?
要使用DeepGEMM,需满足以下依赖项:
-
支持Hopper架构的GPU(sm_90a)。
-
Python 3.8及以上版本。
-
CUDA 12.3及以上(推荐12.8)。
-
PyTorch 2.1及以上。
-
CUTLASS 3.6及以上。
开发代码如下:
# Submodule must be cloned
git clone --recursive [email protected]:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py
安装代码如下:
python setup.py install
完成上述步骤后,即可在Python项目中导入deep_gemm。
接口方面,普通DeepGEMM可调用deep_gemm.gemm_fp8_fp8_bf16_nt函数,支持NT格式(非转置LHS和转置RHS)。对于分组DeepGEMM,连续布局下使用m_grouped_gemm_fp8_fp8_bf16_nt_contiguous,掩码布局下使用m_grouped_gemm_fp8_fp8_bf16_nt_masked。
DeepGEMM还提供了设置最大SM数量、获取TMA对齐大小等工具函数,并支持环境变量如DG_NVCC_COMPILER、DG_JIT_DEBUG等。
除此之外,DeepSeek团队还分享了几种优化方式:
-
JIT设计:所有内核在运行时编译,无需安装时编译,支持动态选择最优块大小和流水线阶段。
-
细粒度缩放:通过CUDA核心两层累加解决FP8精度问题,支持非2的幂次方块大小,优化SM利用率。
-
FFMA SASS交错:通过修改SASS指令的yield和reuse位提高性能。
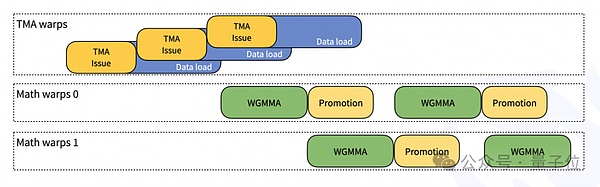
感兴趣的开发者可以访问GitHub链接了解更多详情。
One More Thing
值得一提的是,近期英伟达股价持续下跌:
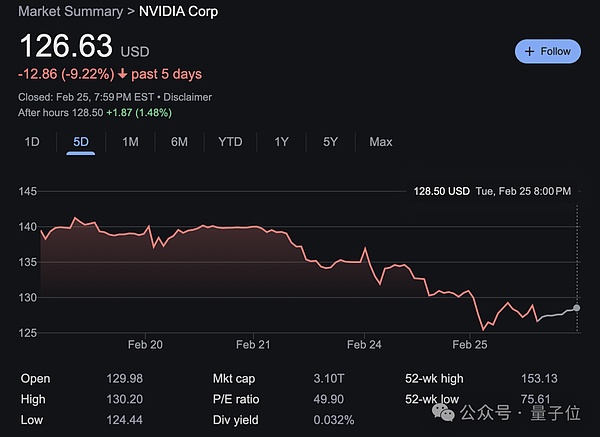
不过,北京时间27日凌晨,英伟达2025财年第四季度业绩报告即将发布,市场对其表现充满期待。
- 1美联储2025年降息对非必需消费品与科技股的深远影响
- 2币安人生上线币安Alpha,三天市值突破1.5亿美元的背后
- 3比特币引领加密货币市场:4.35万亿美元市值背后的战略配置与宏观经济驱动
- 4比特币今日新闻:飙升至历史高点,对冲美元贬值与政策波动成焦点
- 5「币安人生」暴涨背后的流量密码:CZ与何一的推波助澜
- 6OpenAI将ChatGPT重塑为多功能应用平台,推出App SDK与AgentKit
- 7Aster空投计划:打击洗盘交易与市场抛售压力的博弈
- 8Berachain/比特币市场分析(2025-10-05):短期支撑位或成关键
- 9美国通过GENIUS法案:稳定币监管新时代巩固美元数字主导地位
- 交易所
- 币种
| 排名 | 交易所 | 成交额 |
|---|---|---|
| 1 |  币安网 币安网 |
¥1.21万亿 |
| 2 |  欧易OKX 欧易OKX |
¥3,983.11亿 |
| 3 |  HTX HTX |
¥598.54亿 |
| 4 |  Coinbase Coinbase |
¥225.56亿 |
| 5 |  大门 大门 |
¥2,806.59亿 |
| 6 |  Bitget Bitget |
¥2,539.56亿 |
| 7 |  Bybit Bybit |
¥3,129.97亿 |
| 8 |  双子星(Gemini) 双子星(Gemini) |
¥12.50亿 |
| 9 |  Upbit Upbit |
¥176.04亿 |
| 10 |  Crypto.com Crypto.com |
¥771.41亿 |
 泰达币
泰达币 以太坊
以太坊 比特币
比特币 USD Coin
USD Coin Solana
Solana 币安币
币安币 瑞波币
瑞波币 First Digital USD
First Digital USD 狗狗币
狗狗币 大零币
大零币