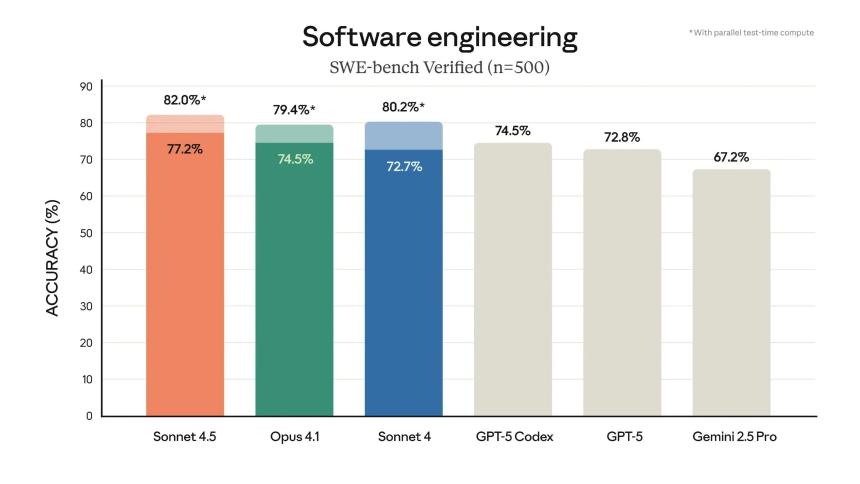
根据 Anthropic 的公告,该模型在 SWE-bench Verified(一项衡量真实世界软件编码能力的基准测试)上的得分为 77.2%。使用并行测试时计算时,该得分可提升至 82%。这使得新模型领先于 OpenAI 和谷歌的最佳产品,甚至超过了 Anthropic 的 Claude 4.1 Opus(根据该公司的命名方案,Haiku 为小型模型,Sonnet 为中型模型,而 Opus 是该系列中最重、性能最强的模型)。
图片:Anthropic
Claude Sonnet 4.5 在 OSWorld 基准测试中也处于领先地位,该基准测试旨在测试 AI 模型在现实世界计算机任务中的性能,得分为 61.4%。四个月前,Claude Sonnet 4 以 42.2% 的得分领先。该模型在推理和数学基准测试中表现出了更强大的能力,并且在金融、法律和医学等特定商业领域的专家中也表现出色。
我们试用了该模型,首次快速测试发现,它能够使用零样本提示生成我们常用的“AI vs Journalists”游戏,无需迭代、调整或重试。该模型生成功能代码的速度比 Claude 4.1 Opus 更快,同时保持了高质量的输出。它创建的应用程序展现出与 OpenAI 输出相当的视觉效果,这与 Claude 早期版本(通常界面不够精致)的界面有所不同。
Anthropic 发布了该模型的多项新功能。Claude Code 现在包含检查点,可以保存进度并允许用户回滚到之前的状态。该公司更新了终端界面,并发布了原生 VS Code 扩展。Claude API 增加了上下文编辑功能和内存工具,使代理能够运行更长时间并处理更高的复杂性。Claude 应用现在支持在对话中直接执行代码以及创建电子表格、幻灯片和文档的文件。
定价与 Claude Sonnet 4 保持不变,为每百万输入代币 3 美元,每百万输出代币 15 美元。所有 Claude 代码更新均面向所有用户开放,而 Claude 开发者平台更新(包括 Agent SDK)也面向所有开发者开放。
Anthropic 还称 Claude Sonnet 4.5 是“我们迄今为止最前沿的模型”,并表示该模型在减少谄媚、欺骗、权力欲和鼓励妄想等令人担忧的行为方面取得了显著进步。该公司还表示,在防御即时注入攻击方面取得了进展,而即时注入攻击被认为是代理和计算机使用能力用户面临的最严重风险之一。
 币安网
币安网 欧易OKX
欧易OKX HTX
HTX Coinbase
Coinbase 大门
大门 Bitget
Bitget Bybit
Bybit 双子星(Gemini)
双子星(Gemini) Upbit
Upbit Crypto.com
Crypto.com 泰达币
泰达币 以太坊
以太坊 比特币
比特币 USD Coin
USD Coin Solana
Solana 瑞波币
瑞波币 First Digital USD
First Digital USD 狗狗币
狗狗币 币安币
币安币 Plasma
Plasma